
While there are a variety of article-length introductions to geometric measure theory, ranging from Federer’s rather dry AMS Colloquium Talks to Fred Almgren’s engaging Questions and Answers to Alberti’s Article for the Encyclopedia of Mathematical Physics, I will take a different approach than has been taken in any of these and introduce geometric measure theory through the vehicle of the derivative.
The Derivative, Geometrically
The derivative that is encountered for the first time in calculus is defined as the limit of a ratio of the “rise” over “run” of the graph of a function. For 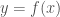



This is visualized as the slope of the secant lines approaching a limit – the slope of the tangent line – as the free ends of those lines approach 

The derivative as 
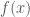
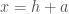

where 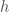

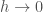
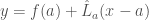
Exercise: use the facts that (1) linear 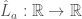


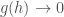
Using the equation above to get
![\left|f(x) - (f(a) + \hat{L}_a(x-a))\right| \leq (\sup_{|s|\in[0,\epsilon]} |g(s)|)|h|](https://s0.wp.com/latex.php?latex=%5Cleft%7Cf%28x%29+-+%28f%28a%29+%2B+%5Chat%7BL%7D_a%28x-a%29%29%5Cright%7C+%5Cleq+%28%5Csup_%7B%7Cs%7C%5Cin%5B0%2C%5Cepsilon%5D%7D+%7Cg%28s%29%7C%29%7Ch%7C&bg=ffffff&fg=444444&s=0&c=20201002)
![h\in[-\epsilon,\epsilon]](https://s0.wp.com/latex.php?latex=h%5Cin%5B-%5Cepsilon%2C%5Cepsilon%5D&bg=ffffff&fg=444444&s=0&c=20201002)
we are able — after some work (see the exercise below) — to get this nice geometric interpretation:

The figure illustrates the fact that the graph of 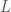

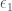

Let’s restate this. Defining
,
to be the ball of radius
,
,
to be the smallest closed cone, symmetrically centered on
, and
to be the angular width of
we have that
f is differentiable at
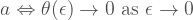
Here is a figure illustrating this:

Exercise: provide the missing details taking us from the above inequality bounding the deviation from linearity to the above statement that {f is differentiable at 
![(x-a,y-f(a)) \in [-\epsilon,\epsilon] \times(-\infty,\infty)](https://s0.wp.com/latex.php?latex=%28x-a%2Cy-f%28a%29%29+%5Cin+%5B-%5Cepsilon%2C%5Cepsilon%5D+%5Ctimes%28-%5Cinfty%2C%5Cinfty%29&bg=ffffff&fg=444444&s=0&c=20201002)
With this shift to a geometric perspective, we are now in a position to take a step in the direction of geometric measure theory.
Note that in our definition the cones contain all of the graph as they narrow down and we zoom in. But what if all we know is that a larger and larger fraction of the graph is in a narrower and narrower cone as we zoom into p? That is precisely the idea that approximate tangent lines capture. We will introduce two different versions of the concept.
Densities as a path to an approximate tangent line
Tangent Cones
The tangent line discussed above is also the tangent cone. The tangent cone of a set in 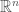
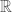

We now define the tangent cone of 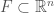
To obtain the tangent cone, begin by translating 
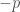

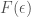



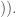
Now define the tangent cone of F at p to be the intersection of 


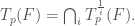
Here is a figure illustrating the key idea:

Note: the tangent cone is centered on the origin, 0, but I will be plotting it as though it were centered on p. Similarly, the tangent lines will sometimes be thought of as linear subspaces (i.e. centered on the origin 0, and other times as the shift of that linear subspace to p.
In the case of a differentiable function 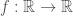
Densities
Now we need 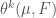
Define 
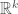
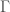

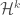
Now,

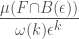
when this limit exists. When the limit does not exist, we work with the limsup and liminf of the right hand side which are called upper and lower densities of F at p and are denoted by 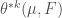
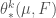
Approximate Tangent Cones
We now define the approximate tangent cone at p to be the intersection of closed cones whose complements intersected with F have density zero at p:
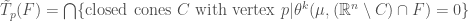
Originally (in this section), we were aiming at having a definition of approximate tangent line that was invariant to (small) pieces of the set F outside the sequence of cones, provided those pieces got small enough, quick enough. Now we can make that more precise. We want a definition of approximate tangent line that ignores such excursions of F provided these excursions have density zero at p. Rather anti-climatically then, here is the definition we have been waiting for (though you might have already guessed it!)
A 1-dimensional set has an approximate tangent line at
When the curve is an embedded differentiable curve, the tangent line and the approximate tangent line are the same.
Remark: in general, when we are dealing with k-dimensional sets in
Exercise: can you create examples of one dimensional sets which have a (density based) approximate tangent line at p but not the usual tangent line at p?
Exercise: prove that a tangent line to a continuous curve is also the (density based) approximate tangent line at p.
Integration as a path to an approximate tangent line
There is different version of approximate tangent k-plane based on integration. (The one dimensional version is of course an approximate tangent line.)
We start with the fact that we can integrate functions defined on

We will say that the set 

for all continuously differentiable, compactly supported 
In the next two figures, we illustrate this for the case of 1-planes – i.e.lines: in the first figure,
Note: solid green lines are the level sets of 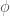



Exercise: can you create an example of a one dimensional curve which has the usual tangent line at p but not an (integration based) approximate tangent line at p?
Closing Note On Hausdorff Measure
We would like a notion of k-dimensional volume or k-dimensional measure. In many cases, the right notion turns out to be k-dimensional Hausdorff measure. We already know what 1,2, and 3-dimensional measure is as long as the objects we are measuring are regular enough, like subsets of lines, rectangles, and cubes. It does not seem too much of a stretch to think that we can extend these measures to things that are somewhat wiggly. That is, we can still easily imagine measuring the length of a subset of a smoothly turning curve, or the area of a piece of a surface that undulates slowly. Hausdorff measure permits us to measure not only such smooth sets (giving the same result as any reasonable extension of the usual Lebesgue measures to the nice cases), but also to measure very wild sets (like fractals).
How to compute the k-dimensional Hausdorff measure of 
- Cover A with a collection of sets
, where
. Here,
is the diameter of
.
- Compute the k-dimensional measure of that cover:
- Define
where the infimum is taken over all covers whose elements with maximal diameter d.
- Finally, we define:

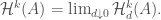
Remark: Suppose that for any 




Here is a figure illustrating Hausdorff measures:

Clearly, this can be difficult to compute. It turns out though that in 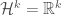

Exercise: Show that if 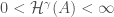
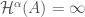

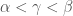
You must be logged in to post a comment.